
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
Tags
- 코드트리
- 이것이자바다9장
- 백준
- 백준9012
- 냅색알고리즘
- 가운데를말해요
- 이것이자바다
- 컴퓨터비전
- 카카오코테
- java
- 백준괄호
- 확인문제
- BOJ
- 운영체제
- BOJ1655
- 윤곽선검출
- 코테
- 딥러닝
- 합성곱연산
- 이것이자바다확인문제
- KT포트포워딩
- 2019카카오코테
- 백준10828
- 웹개발기초
- 코딩테스트실력진단
- 백준스택
- 백준가운데를말해요
- 스파르타코딩클럽
- 백준평범한배낭
- 백준온라인저지
Archives
- Today
- Total
코딩하는 락커
09. CPU 스케줄링: Chapter 5. CPU Scheduling (Part 1) 본문
5.1 기본 개념
- CPU 스케쥴링은 다중 프로그램 운영체제의 기본이 됨
- 운영체제는 CPU를 프로세스 간에 교환함으로써 컴퓨터를 보다 생산적으로 만듦
- 다중 프로그래밍의 목적은 CPU 이용률 최대화 하기 위해 항상 실행중인 프로세스를 가지게 하는 것
CPU - I/O 버스트 사이클
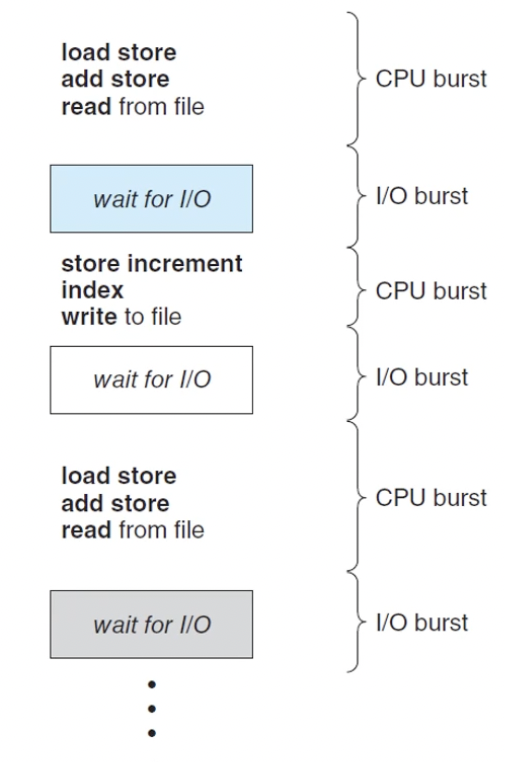
- 프로세스 실행은 CPU 실행(CPU 버스트)과 I/O 대기(I/O 버스트)의 사이클로 구성됨
- 위 그림의 프로세스의 과정
- CPU 버스트로 시작
- I/O 버스트가 발생
- 또 다른 CPU 버스트가 발생
- 또 다른 I/O 버스트가 발생
- ...
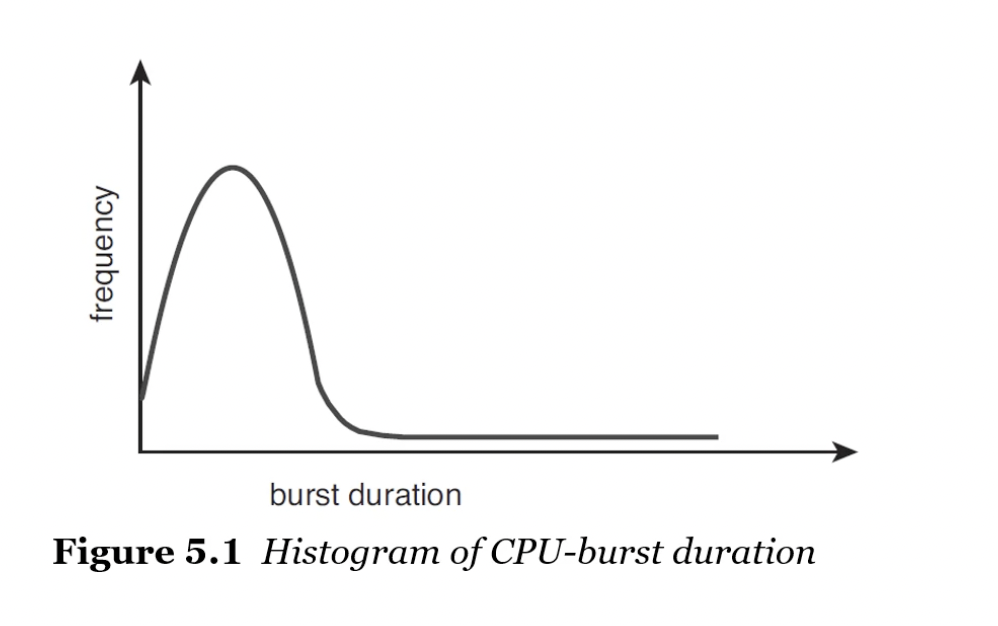
- CPU 바운드와 I/O 바운드
- CPU 바운드: CPU 버스트가 많은 프로세스
- I/O 바운드: I/O 버스트가 많은 프로세스
- 위 그림은 CPU 버스트의 지속 시간을 측정한 그래프를 나타냄
- 짧은 CPU 버스트는 많이 있음
- 긴 CPU 버스트는 적게 있음
- I/O 바운드에는 짧은 CPU 버스트가 많음
- CPU 바운드에는 긴 CPU 버스트가 많음
CPU 스케쥴러
- CPU가 유휴 상태가 될 때 마다 운영체제는 레디 큐에 있는 프로세스 중 하나를 선택해 실행해야 함
- 선택 절차는 CPU 스케쥴러에 의해 수행됨
- 스케쥴러는 실행 준비가 되어 있는 메모리 되어 내의 프로세스 중에서 선택하여 이들 중 하나에게 CPU를 할당함
- 레디큐 구현 알고리즘
- FIFO 큐
- Priority 큐
- 트리
- 연결 리스트
선점 및 비선점 스케쥴링
- CPU 스케쥴링 결정이 발생할 수 있는 4가지 상황
- 한 프로세스가 running 상태에서 waiting 상태로 전환될 때 (ex. I/O 요청시, 자식 프로세스 종료를 기다리기 위한 wait() 호출시)
- 한 프로세스가 running 상태에서 ready 상태로 전환될 때 (ex. 인터럽트 발생시)
- 한 프로세스가 waiting 상태에서 ready 상태로 전환될 때 (ex. I/O 종료시)
- 한 프로세스가 terminate 될 때
- 비선점nonpreemptive과 선점preemptive
- 비선점nonpreemptive
- 상황 1,4의 경우
- 선택의 여지가 없는 경우
- 자의적인 context switch
- 선점preemptive
- 상황 2,3의 경우
- 선택의 여지가 있는 경우
- 타의적인 context switch
- 비선점 스케쥴링
- CPU가 한 프로세스를 할당되면 프로세스가 종료되거나 대기 상태로 전환해 CPU를 방출할 때 까지 점유하는 경우
- 선점 스케쥴링
- CPU가 한 프로세스를 할당되어 있는 상황에서 CPU를 다른 프로세스가 강제로 점유하는 경우
- 비선점nonpreemptive
- Windows, macOS, Linux, Unix 등 거의 모든 최신 운영체제들은 선점 스케쥴링을 사용함
디스패처
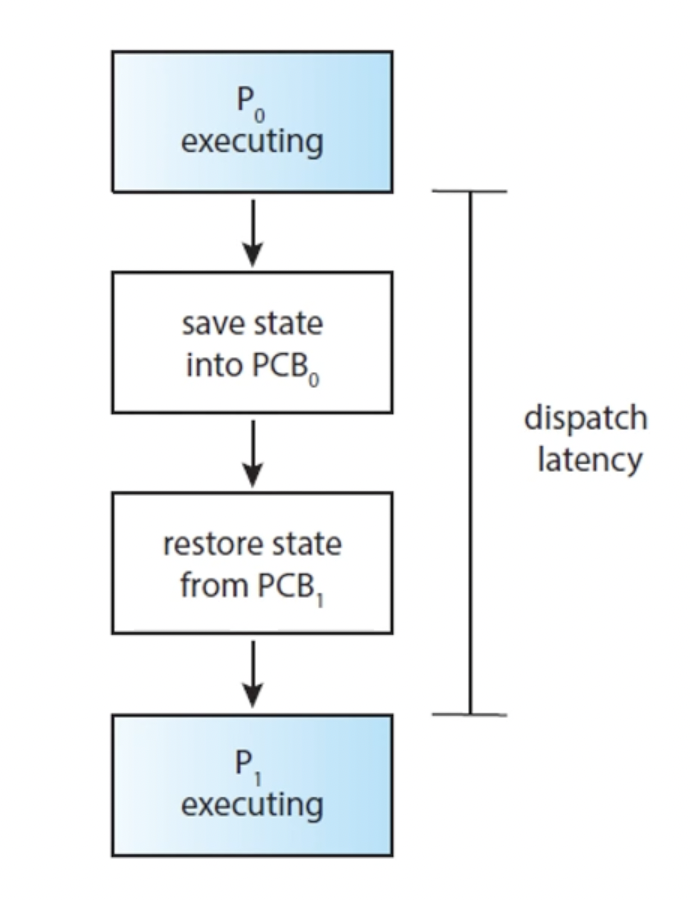
- 디스패처: CPU 코어의 제어를 CPU 스케쥴러가 선택한 프로세스에 주는 모듈
- CPU 스케쥴링 기능에 포함된 요소
- 디스패처가 하는 작업
- 한 프로세스에서 다른 프로세스로 context switch하는 일
- 사용자 모드로 전환하는 일
- 프로그램을 다시 시작하기 위해 사용자 프로그램의 적절한 위치로 이동jump하는 일
- 디스패처는 모든 프로세스의 문맥 교환 시 호출되므로 최대한 빨리 수행되어야 함
- 디스패치 지연: 디스패처가 하나의 프로세스를 정지하고 다른 프로세스의 수행을 시작하는데까지 소요되는 시간
vmstat 1 3
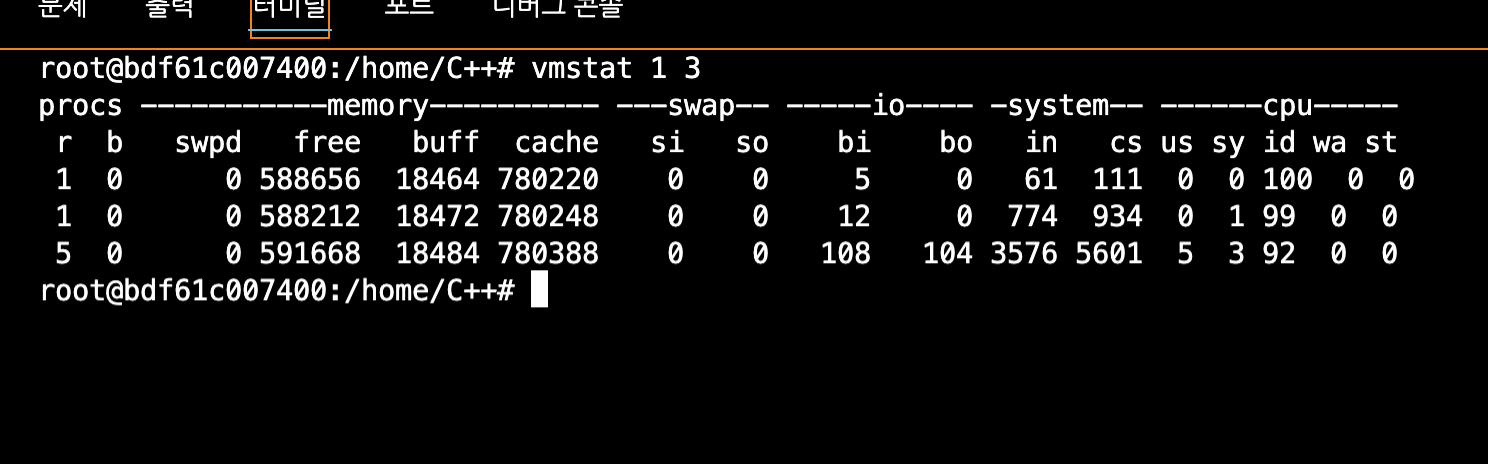
- 위 그림은 vmstat 1 3을 이용하여 1초 단위로 3개의 Linux 환경에서 문맥 교환 횟수를 출력한 결과를 나타냄
- 문맥교환 cs
- 0~1초 : 61번
- 1~2초: 934번
- 2~3초: 5601번
cat /proc/{pid}/status

- 위 그림은 cat /proc/1/status을 이용하여 pid = 1인 프로세스의 자발적 문맥 교환 횟수와 비자발적 문맥 교환 횟수를 출력한 결과를 나타냄
- 자발적 문맥교환voluntary_ctxt_switches: 122
- 비자발적 문맥교환nonvoluntary_ctxt_switches: 2
5.2 스케쥴링 기준
- CPU 이용률utilization
- 처리량throughput
- 단위 시간당 완료된 프로세스의 개수
- 총처리 시간turnaround time
- 프로세스의 제출 시간(레디큐에 도달한 시간)과 완료 시간의 간격
- SUM(레디큐에서 대기한 시간 + CPU에서 실행하는 시간 + I/O 시간)
- 대기시간waiting time
- 레디 큐에서 기다린 시간의 합
- 응답 시간response time
- 하나의 request를 제출한 후 첫번째 응답이 나올 때까지의 시간
- 응답이 시작되는 데까지 걸리는 시간
5.3 스케쥴링 알고리즘
선입선처리 스케쥴링, FIFO(First-Come, First-Served Scheduling)
- CPU를 먼저 요청하는 프로세스가 CPU를 먼저 할당받음
- FIFO 큐로 쉽게 관리할 수 있음

- 위 그림은 시간 0에 도착한 프로세스의 집합임
- P1 -> P2 -> P3 순으로 도착

- 위 그림은 이 경우의 FCFS를 사용한 프로세스 처리 시간을 간트 차트를 나타냄
- 대기시간
- P1: 0msec
- P2: 24msec
- P3: 27msec
- 평균 대기시간: (0+24+27)/3 = 17msec
- 총처리시간
- P1: 24msec
- P2: 27msec
- P3: 30msec
- 평균 총처리시간: (24+27+30)/3 = 27msec

- P2 -> P3 -> P1 순으로 도착했다고 가정
- 위 그림은 이 경우의 프로세스 처리 시간을 간트 차트로 나타냄
- 대기시간
- P1: 6msec
- P2: 0msec
- P3: 3msec
- 평균 대기시간: (6+0+3)/3 = 3msec
- 총처리시간
- P1: 30msec
- P2: 3msec
- P3: 6msec
- 평균 총처리시간: (30+3+6)/3 = 13msec
- 문제점
- FIFO 스케쥴링에서 평균대기시간은 최소가 아님
- CPU 버스트 시간에 따라서 평균대기 시간이 달라짐
- 동적 상황에서 성능이 떨어짐
- 1개의 CPU 바운드 프로세스와 다수의 I/O 바운드 프로세스가 있다고 가정
- CPU 바운드 프로세스가 I/O 바운드 프로세스보다 먼저 레디 큐에 도착했을 경우, 다수의 I/O 바운드 프로세스는 짧은 CPU 이용을 위해서 CPU 바운드 프로세스가 끝날 때 까지 기다려야함
- convoey effect: 모든 다른 프로세스가 하나의 긴 프로세스가 CPU를 양도하기를 기다리는 것
- 비선점형 알고리즘이므로 각 프로세스가 규칙적으로 CPU의 몫을 얻는 것이 중요한 대화형 시스템에서 특히 문제가 됨
최단 작업 우선 스케쥴링, SRF(Shortest-Job-First Scheduling)
- CPU가 이용 가능해지면 가장 작은 CPU 버스트를 가진 프로세스에 할당함
- 동일한 길이의 CPU 버스트를 가질 경우 선입 선처리 스케쥴링 적용

- 위 그림은 시간 0에 도착한 프로세스의 집합임
- P1 -> P2 -> P3 -> P4 순으로 도착
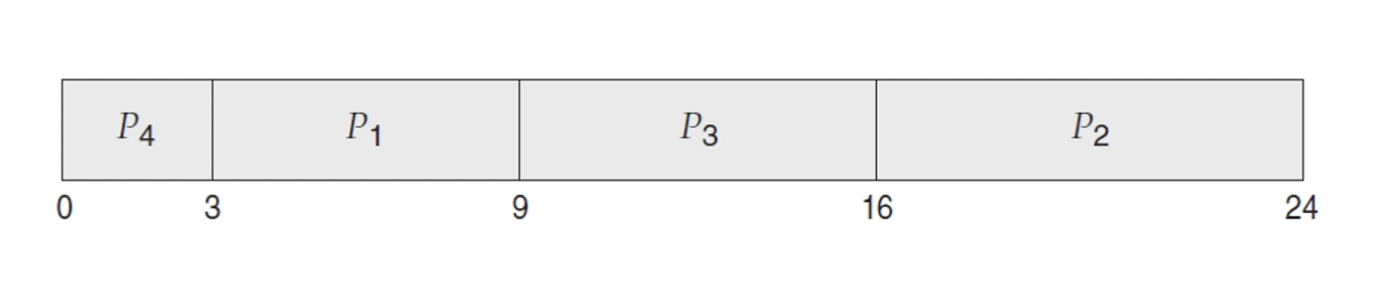
- 위 그림은 이 경우의 SJF를 사용한 프로세스 처리 시간을 간트 차트를 나타냄
- 대기시간
- P1: 3msec
- P2: 16msec
- P3: 9msec
- P4: 0msec
- 평균 대기시간: (3+16+9+0)/4 = 7msec
- 총처리시간
- P1: 9msec
- P2: 24msec
- P3: 16msec
- P4: 3msec
- 평균 총처리시간: (9+24+16+3)/4 = 13msec
- 짧은 프로세스를 긴 프로세스의 앞으로 이동함으로써, 짧은 프로세스의 대기 시간을 긴 프로세스의 대기 시간이 증가하는 것보다 줄일 수 있음
- 결과적으로 평균 대기 시간이 줄어듬
- SJF 알고리즘은 최적이지만 다음 CPU 버스트의 길이를 알 방법이 없기 때문에 CPU 스케쥴링 수준에서는 구현 불가
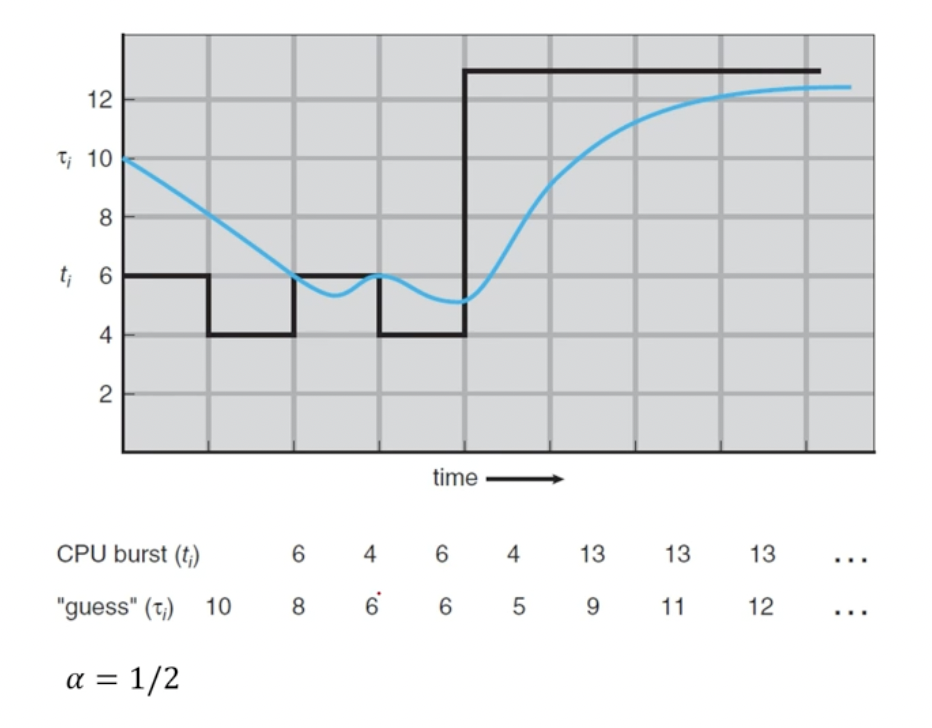
- 그러나 그 값을 이전의 버스트 길이와 비슷하다고 예측하여 근사치를 계산할수 는 있음
- CPU 버스트는 일반적으로 측정된 이전의 CPU 버스트의 길이를 지수평균(ex-ponential average)한 것으로 예측
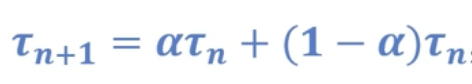
- Tn+1 = a* tn + (1-a)Tn
- Tn+1: 다음 CPU 버스트에 대한 예측값
- tn: n번째 cpu 버스트의 길이
- Tn: 현재 CPU 버스트에 대한 길이
- a = 0일경우
- Tn+1 = Tn
- 현재의 조건이 중요시 됨
- a = 1일 경우
- Tn+1 = tn
- 현재의 CPU 버스트 값이 중요시 됨
- a = 1/2인 경우
- 최근의 CPU 버스트 값과 이전의 CPU 버스트 값이 같은 가중치를 가짐
- SJF 알고리즘은 선점형이거나 비선점형일 수 있음
- 앞의 프로세스가 실행되는 동안 새로운 프로세스가 준비 큐에 도착하면 선택 발생
- 새로운 프로세스가 현재 실행되고 있는 프로세스의 남은 시간보다 짧은 CPU 버스트를 가질 때
- 선점형 SJF의 경우: 현재 실행하고 있는 프로세스를 선점
- 비선점형 SJF의 경우: 현재 실행하고 있는 프로세스가 자신의 CPU 버스트를 끝내도록 허용함 -> 최소 잔여 시간 우선 스케쥴링(SRTF, shortest remaining time first)
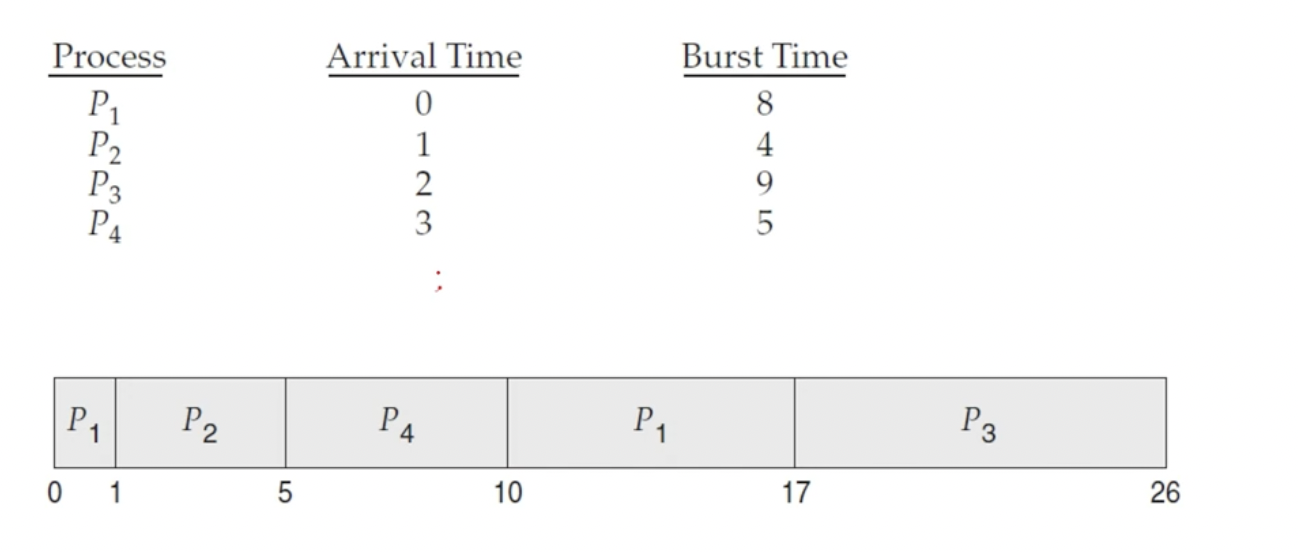
- 위 그림은 시간 0,1, 2, 3에 차례로 도착한 프로세스의 집합과 간트차트를 나타냄
- 대기시간
- P1: 9msec
- P2: 0msec
- P3: 15msec
- P4: 3msec
- 평균 대기시간: (9+0+15+3)/4 = 6.5msec
- 총처리시간
- P1: 17msec
- P2: 4msec
- P3: 24msec
- P4: 7msec
- 평균 총처리시간: (17+4+24+7)/4 = 13msec
- 평균시간이 7.75인 비선점형 SJF 스케쥴링에 비해 평균 대기시간이 적음
'📀 운영체제' 카테고리의 다른 글
| 11. 프로세스 동기화: Chapter 6. Synchronization Tools (Part 1) (0) | 2022.06.06 |
|---|---|
| 10. 스케줄링 알고리즘: Chapter 5. CPU Scheduling (Part 2) (0) | 2022.06.06 |
| 07 ~ 08. 쓰레드의 이해: Chapter 4. Thread & Concurrency (Part 1 ~ Part 2) (0) | 2022.05.30 |
| 06. 프로세스간 통신의 실제: Chapter 3. Processes (0) | 2022.05.24 |
| 05. 프로세스간 통신: Chapter 3. Processes (0) | 2022.05.22 |
'📀 운영체제' Related Articles
more




Comments